DeepSeek AI开发的费用为16亿美元,揭穿了负担能力神话
DeepSeek的新聊天机器人对AI市场产生了重大影响,由于其竞争优势,NVIDIA最大的股价下跌之一。 DeepSeek在以令人惊讶的方式回答问题的希望中引入了迅速将自己定位为行业中强大的参与者。
 图片:ensigame.com
图片:ensigame.com
DeepSeek模型的区别是其创新的建筑和培训方法。该公司采用多种高级技术,包括:
多语预测(MTP) :此方法允许模型通过分析句子的不同部分一次预测多个单词,从而显着提高了准确性和效率。
专家(MOE)的混合物:利用256个神经网络,每个令牌处理任务都激活了8个,该体系结构加快了AI训练并增强了性能。
多头潜在注意力(MLA) :该机制着重于句子的最重要部分,多次提取关键细节以减少缺少重要信息的机会,从而捕获输入数据中的重要细微差别。
 图片:ensigame.com
图片:ensigame.com
DeepSeek是一家著名的中国初创公司,声称已经开发了一种竞争性的AI模型DeepSeek V3,仅使用2048个图形处理器,培训的成本最低为600万美元。但是,半分析的分析师发现该公司实际上经营着庞大的计算基础设施,其中包括约50,000个NVIDIA HOPPER GPU,其中包括10,000 H800单位,10,000 h100s和其他H20 GPU,以及额外的H20 GPU,分布在多个数据中心。这些资源不仅用于AI培训,还用于研究和财务建模。
DeepSeek对服务器的总投资估计为16亿美元,运营费用达到9.44亿美元。作为中国对冲基金高潮的子公司,DeepSeek在2023年被旋转,专注于AI技术。与许多依赖云服务的初创公司不同,DeepSeek拥有其数据中心,这可以更好地控制AI模型优化和更快的创新实现。该公司保持自筹资金,提高其灵活性和决策速度。
 图片:ensigame.com
图片:ensigame.com
DeepSeek还吸引了顶尖人才,一些研究人员每年收入超过130万美元,主要来自中国领先的大学。该公司对只有600万美元培训DeepSeek V3的主张被认为是不现实的,因为它仅在预培训期间占用GPU使用,并排除了其他重大成本,例如研究,改进,数据处理和整体基础架构。
自开始以来,DeepSeek已在AI开发方面投资了超过5亿美元。它的精益结构可以快速有效地实施AI创新,使其与更大,更官僚的公司区分开来。
 图片:ensigame.com
图片:ensigame.com
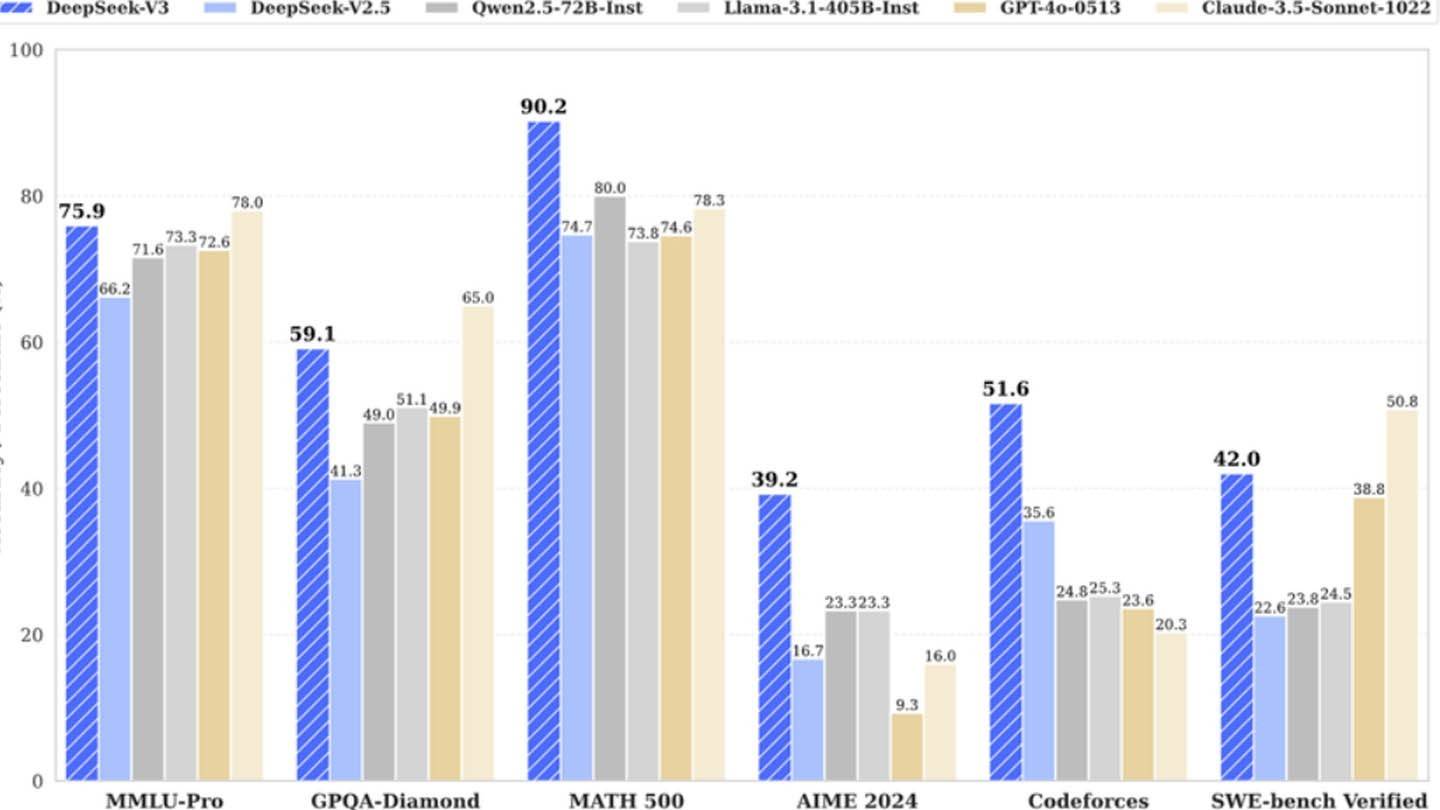
DeepSeek的成功展示了一家资金充足的独立AI公司如何挑战行业领导者。尽管公司的成就令人印象深刻,但专家们建议,对AI模型开发的“革命预算”的主张被夸大了。 DeepSeek的成本虽然很大,但仍低于其竞争对手的成本;例如,DeepSeek的R1车型的培训成本为500万美元,而Chatgpt4o的培训成本为1亿美元。



![Taffy Tales [v1.07.3a]](https://imgs.anofc.com/uploads/32/1719554710667e529623764.jpg)